Klaus! How can I get a hold of you re: Backblaze related things?
You can catch me at klauspost at gmail dot com
Thanks for this. I love when people write "Our Java library for (...) is as fast as a C implementation". Java is slow and not memory efficient if you really care about speed and performance. Say it loud and proud.
If anyone is interested, I wrote about Error Correcting Codes and Reed-Solomon using a different approach to understand the concept here: https://monades.roperzh.com...
Some of the links refer to RS "original view" encoding (a message based generator polynomial used to generate additional data points), while CDs, DVD's, hard drives, and tape drives use RS "BCH view" encoding (a fixed polynomial known to both encoder and decoder used to generate a remainder which is appended to data similar to CRC). One of the links refers to "original view" Berlekamp Welch decoder but this was later improved with Gao's extended Euclid based "original view" decoder. Link to wiki article:
https://en.wikipedia.org/wi...
Can you talk a bit more about how you decided to go with 17+3, and how the blocks of data are allocated across independent disks and independent pods in a vault?
You should definitely check out this paper, as your application seems like it's right in line with their analysis ("sealed blocks"): http://www.cs.jhu.edu/~okha.... The money quote: "Regardless, we do draw some important conclusions from the work. The most significant one is that reading from the P drive or using standard Reed-Solomon codes is not a good idea in cloud storage systems. If recovery performance is a dominant concern, then the Liber8tion code is the best for RAID-6, and Generalized RDP is the best for three fault-tolerant systems."
Don't know for sure. I bet that their pods hold 20 drives, or that 20 is one of the magic dimensions of their storage matrix. That's where the 20 comes from. If you lose a whole disk, you have to read all of the other disks to reconstruct the missing disk. This is enough greater load that the chance of a second failure while doing the rebuild is signficant. So add a third parity shard so that you still have bit rot protection when you have 2 failures at once.
If you are *really* serious you put each disk of a shard set in a different rack so that one spasming power supply can't take down the entire set. Then you make sure that each rack is on a separate circuit breaker; that pods are redundantly connected to multiple switches...
Thanks for the link. I'll have to read that paper carefully, but my first impression is that RDP supports at most two drive failures. For our current vault deployment, we think that three parity shards are required to provide the degree of safety we need.
We analyzed the potential failure scenarios, and found that 17+3 balanced cost and operational complexity, while providing the level of file durability we needed.
Why not use Raid 6 syndrome encoding instead of modified Vandermonde matrix encoding? For the example, the last two rows would be {1,1,1,1} and {1,2,4,8}. For a third parity,row {1,4,10,40} (in hex). The advantage of this is that a single erasure of any data row or the first parity row can be regenerated XOR'ing 4 rows of data. For a 2 data row erasure case, two 2 by 2 matrices are created, one of them inverted, then the two multiplied to create a 2 by 2 correcting matrix, which is then multiplied by the 2 non-erased rows by 4 column matrix.
I ported the code to Squeak. All tests are green!
Find this port in the Cryptography repository, loadable in Squeak: http://www.squeaksource.com.... The package names are CryptographyRSErasure and CryptographyRSErasureTests.
I refactored the codingLoops, in a significant way. They are all implemented with single coding & checking loops. The difference between table lookup and Galois computation are isolated to nee compute methods in each of two new superclasses: RAErasureTableCodingLoop & RSErasureExpCodingLoop. The crux of a good implementation is that some codingLoops require to store accumulated values in the output array for subsequent retrieval in adding the old value to the new value component.
It is very slow (~ 5 MB/s, although some isParityCorrect benches at 100 MB/s).
RSErasureOutputInputByteTableCodingLoop encodeParity 3.0 MB/s
RSErasureOutputInputByteTableCodingLoop isParityCorrect 101.15 MB/s
Wow, check these numbers!
TEST: RSErasureOutputByteInputTableCodingLoop isParityCorrect
warm up...
200000 bufferSize, 6 MBs, 2 Seconds, 2 passes, 3.0 MB/s
200000 bufferSize, 6 MBs, 2 Seconds, 2 passes, 3.0 MB/s
testing...
200000 bufferSize, 571 MBs, 2 Seconds, 168 passes, 285.5 MB/s
200000 bufferSize, 571 MBs, 2 Seconds, 168 passes, 285.5 MB/s
200000 bufferSize, 571 MBs, 2 Seconds, 168 passes, 285.5 MB/s
200000 bufferSize, 571 MBs, 2 Seconds, 168 passes, 285.5 MB/s
200000 bufferSize, 571 MBs, 2 Seconds, 168 passes, 285.5 MB/s
200000 bufferSize, 571 MBs, 2 Seconds, 168 passes, 285.5 MB/s
200000 bufferSize, 571 MBs, 2 Seconds, 168 passes, 285.5 MB/s
200000 bufferSize, 571 MBs, 2 Seconds, 168 passes, 285.5 MB/s
200000 bufferSize, 571 MBs, 2 Seconds, 168 passes, 285.5 MB/s
200000 bufferSize, 571 MBs, 2 Seconds, 168 passes, 285.5 MB/s
AVERAGE: 285.5 MB/s
So I am working on a plugin for the Galois operations. I am also looking to zxing to implement an error correction version, for use over radio and SATCOM.
Looking to errorCorrection, I have gotten zxing's GenericGF, GenericGFPoly, RSFECEncoder & RSFECDecoder implemented & now working on the Tests. All protocol interfaces are declared, working to implement them, including, or especially auto-tests.
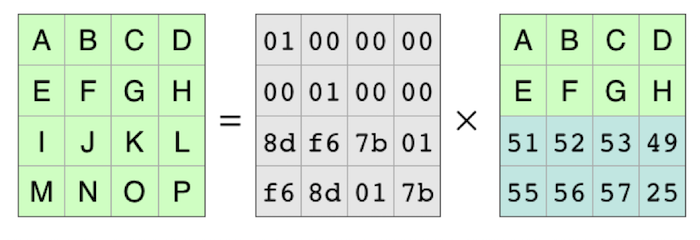
i got a simple question. can please u explain if the data stream is 'ABCDE FGHIJ KLMNO PQRST' then how this works . its not clear to me how the coding matrix that you multiply with your data matrix is generated ? i am a newbie , help will be really appreciated . What i really want to know is how that extra two rows generated
The matrix in the example is a 6 x 4 Vandermonde matrix multiplied by the inverse of the upper 4 x 4 so that upper 4 x 4 part is the identity matrix. This modified 6 x 4 matrix is used to multiply the data shards treated as a 4 x n matrix, where n is the number of bytes in each shard, to generate the encoded set of shards as a 6 x n matrix. This is explained with an example using a 4 x 8 shard matrix here (link):
https://stackoverflow.com/q...
How do you manage to create the shards if data ain't multiple of the word size ?
In the github example code, the shards contain the file size (a 4 byte integer) followed by the file data, with each shard padded to a word (4 byte int) boundary. The example code assumes the file will fit in a buffer. I assume actual server code would use a larger file size parameter (8 byte integer), and would be able to handle large files that don't fit in memory.
I ported the code to C# in https://github.com/claunia/... and after doing it I've found it does not fullfil my needs, that are, the CompactDisc Reed Solomon, that after reading and re-reading all documentation I still do not understand how to implement :(
Sorry for the last response. There are two different codes, both called Reed Solomon, "original view" and "BCH view". The method on this web site is using "original view", but compact disc, hard drives, tape drives, ..., use "BCH View". The wiki article explains this, along with examples for encoders and decoders (correction).
https://en.wikipedia.org/wi...
"Native Software
Java is responsible for 91%* of
security attacks. Backblaze's code is native to Mac and PC and doesn't use Java."
Given the scale you operate at, is it practical for you to implement RS in hardware, and market your own line of controller cards?
We already know the source code, mentioned here and hosted in github, is licensed under MIT/Expat License.
May I know what's the license for the image files in this blog post?
For example:
- https://www.backblaze.com/b...
{kind=link}
I hope image files are also under MIT/Expat License. So we can use them together with the source code.
Could you kindly help to confirm it? Thank you!
Thanks Brian, Backblaze for releasing this under the MIT license. The code is really well written and well structured. I have created a port to Javascript for Node.js with an optional C++ native binding: https://www.npmjs.com/packa...
How do you determine what the "parity pieces" of the generator matrix are?
Thanks for the help.
why don't you guys just use jerasure ?
A couple of micro-optimizations: For divide() in galois.java, you can remove the if < 0 condition and unconditionally add 255 to the difference because the EXP_TABLE is duplicated. Similarly, in exp(), log_result by can be reduced by log_result=(log_result&0xFF)+(log_result>>8), instead of the iterative reduction loop.[[And you don't need to add one additional byte entry (a final 1) in the EXP_TABLE to cover the case when log_result == 0xFFFF, because the product of log(a)*n is always smaller. The comment about the range of values in LOG_TABLE is incorrect: the largest value is 254, not 255, and the comment in EXP_TABLE even says that.]] These changes have only a tiny effect on performance, though, as the functions are only used to compute the matrices.
Quick and fairly direct C++ port, with some SSE3 intrinsics. https://github.com/DrPizza/...
On a Core i7-2600, 10 data blocks, 4 parity blocks, 16 MiB per block, across 8 threads it goes at about 7-8 GiB/s. For 17 data, 4 parity, 200 kiB block size, 8 threads hit about 10 GiB/s.
It is not very extensively tested. Bugs would not tremendously surprise me.
Hi,
How do you solve the problem of partial writes? If the node crashed while writing the file into
shards, then shards (both data and parity) may contain partial data and then it may not be possible
to recover data from parity (as we don't know whether parity is old, new or partial).
So is there any front end logging used?
A great explanation, but I have tons of questions now! :)
So, you have to store the encoding matrix, as well as the original data, right? Or is that computed from the original data, whatever parts are still available? Because if you have to store that as well, that practically doubles the size of the storage needed, right?
Or, can you reverse-engineer the encoding matrix from the parity that's left? Or do you store the encoding matrix AND the parity? In the above example, you have 16 bytes original data and 8 bytes parity and 16 bytes of encoding matrix -- so a ratio of 16:24 original data:encoded data, right?
I'm probably really off on this. I just saw a chicken and egg problem if you have to store the encoding matrix as well as the original data, then what stops you from losing the encoding matrix due to disk corruption as well? And then you have to have an encoding matrix encoding matrix?
Ok, my eyes are crossed. ;)
The encoding matrix is constant, given the number of data shards and the number of parity shards.
In our library, when you create a ReedSolomon object, and give it the data count and parity count, it computes the encoding matrix for that configuration. There is a fixed, reproducible algorithm to do that, so you don't have to store the encoding matrix with the data.
I have released a fully compatible Go port of the library & tests. It is an order of magnitude faster, mainly since I can use SSE3 assembler.
Thanks for releasing this. The library was very easy to understand, and cleanly written and I didn't find any problems while porting the code.
I have written an extensive "usage" guide, and also described a bit more what you should mind when implementing the library. Together with this excellent blog post it should be a good start.
The project can be found at https://github.com/klauspos...